codemlのCodonFreqの選択について
選択圧(淘汰圧)を解析するためにPAMLのcodemlがよく使われる。 いくつか日本語でも解説が書かれており、それに従って使っていることが多かったが、CodonFrequencyについての記述は日英共に解説が少ない。どうやって選択すべきか調べていたが、灯台もと暗しで知人がきちんと統計的なモデル選択の…

選択圧(淘汰圧)を解析するためにPAMLのcodemlがよく使われる。 いくつか日本語でも解説が書かれており、それに従って使っていることが多かったが、CodonFrequencyについての記述は日英共に解説が少ない。どうやって選択すべきか調べていたが、灯台もと暗しで知人がきちんと統計的なモデル選択の…
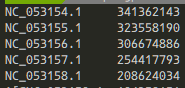
参考: Sequence length from Fasta マルチFASTA で、それぞれの配列の長さを出してほしい時がある。 そういったときに簡単に出力してくれるのがbioawkだ。 で、仮想環境上にインストール。 で、出力してくれる。 全部出すと長い場合、パイプで繋いでやって欲しい部分に絞って…
バイオインフォマティクス関連で、稀にtwoBit file (2bit file) を使用する機会がある。 通常、ゲノムファイルなどのシーケンスデータはFASTA形式で頒布されているが、一部において効率的・高速な解析のためにtwoBit fileと呼ばれる形式が使用される。 UCSCによると、「ゲノ…
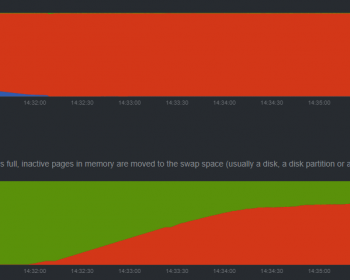
タイトルの通り。これからハイギョのRNA-seq解析などをしたいという稀有な研究者に向けたメモ。 BLAST 正直BLASTするだけならそこまでスペックはいらない。他のゲノムと比べると時間がかかるが、数コアでも十分可能。 STAR を用いた RNA-seq マッピング RNA-seqでもTrinit…

2022/06/30 Seqkit のソート項目を追記2025/02/04 最新版へのリンクへ修正 lastzについての日本語ドキュメントが少ないので備忘録として。 lastzはWhole genomeレベルでのアライメントができるツールである。 結構古くからあり有名なのでこの辺の説明は割愛。今も開…

最近は転移因子(TE、トランスポゾン)の話が連日続いているが、今回は前回の記事で紹介した機械学習によるTE分類ツールの1つ、DeepTE (Yan et al., 2020) を実際に使ってみる。 Yan, H., Bombarely, A., & Li, S. (2020). D…

転移因子(トランスポゾン、TE)はゲノムのある位置からある位置へと飛んでいくというDNA配列である。様々な真核生物においてゲノムに存在し、様々な役割を担っていたり、あるいは単純に「ジャンクDNA」であるようなものも存在する(最初はジャンクとして見られていたけど近年になって様々な役割が明らかにされてき…

ゲノム中の反復配列、トランスポゾン等を検出するソフトは色々と開発されている。代表的なものにRepeat Maskerだったり、RepeatScout、WindowMasker、RepeatModeler等々ある。 それぞれライブラリをベースに検出を行ったり、あるいは denovo 法に基づいていたり…
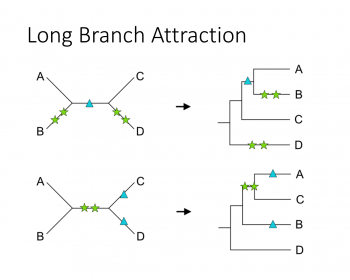
分子系統樹を作成する時、特に何も考えずにツールに突っ込んで得られたデータの樹形を見ているということはないだろうか? 系統樹に関する既知の問題点として「Long branch attraction」という現象が古くから(50年くらい前)知られている。ロングブランチアトラクション、の日本語訳はまだ当てら…
先日またRNA-seqを外注した。 FASTQCでクォリティチェックを行ったところ、以下のように、”Overrepresented sequences”に関する表示が出ていた。なにやら”GGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGG…




![【Qiskit】マルチオミクス解析を量子機械学習でやる①[環境構築・基礎]](https://kimbio.info/wp-content/uploads/2024/05/2203027-100x100.jpg)


