
※本記事はバイオインフォマティクス Advent Calendar 2019の1日目の記事です。何も考えず一番乗り~ってしてしまいましたがプログレス発表や期末レポートの締め切り等が重なって、非常に多忙な中書いた記事なので後日加筆・修正が入るかもしれません
2020/01/03 製作者ご本人からの解説・補足を頂いたので追記しました
2020/07/14 Bedfile のRGB値について追記
2023/07/25 オプションについての詳細を追記
ある遺伝子の配列を持っていて、それと似た配列をゲノムデータから得たい! というとき、その遺伝子が多数のエキソンからなる場合、BLASTを使うと細切れの配列しか取れてこなくもどかしい思いをすることがある。
そんなときに役立つツールを今回紹介する。
あるクエリー(アミノ酸配列)をゲノムデータに対してBLASTし、イントロンエキソン構造を考慮し、偽遺伝子化しているかどうかまで判定してくれるパイプラインソフトウエア、“FATE”だ。
FATEのインストール
FATEをインストールするためには以下のソフトウエアが予めインストールされている必要がある。
- perl (Thread::Queue)
- blast+
- exonerate
- wise2
これらはUbuntuでは全てパッケージが配布されているので
$ sudo apt install ncbi-blast+ $ sudo apt install exonerate $ sudo apt install wise
でインストール可能である。(macの人は補足参照)
Perlと Thread::Queue のインストールもそこまで難しくはなく、マニュアルにある通り
$ cpan > reload index > upgrade Thread::Queue > q
でインストールができた。Perlは普通に最新版を入れれば良い。
FATE自体のインストールもGitHubからcloneしてPATHを通してやれば良い。
$ git clone https://github.com/Hikoyu/FATE.git
(PATHの通し方は記載しないがFATEのディレクトリに通せば良い)
FATEの機能
FATEは Framework for Annotating Translatable Exons の略である。
FATE自体は論文化されていないようで、ある別の論文中で触れられている。
Moriya-Ito, K., Hayakawa, T., Suzuki, H., Hagino-Yamagishi, K., & Nikaido, M. (2018). Evolution of vomeronasal receptor 1 (V1R) genes in the common marmoset (Callithrix jacchus). Gene, 642, 343-353.
機能としては search 、filter 、 predict の3つがある。
Searchの機能
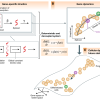
FATEでゲノム上でのクエリの位置の取得
Searchはその名の通り、ゲノムデータ上から配列を探して取ってくる。具体的には、まずクエリとなるアミノ酸配列をゲノムデータに対してBLASTし、イントロン・エキソン構造を考慮しながらヒットするリージョン(領域)を取得する。
実際に動かす例を取り上げる。
$ fate.pl search -p 8 -g genewise -o 60 -v 1 -h tblastn [ゲノムデータ] [クエリ] > out.bed
ゲノムデータは塩基配列、クエリはアミノ酸配列のFASTA形式のファイルで与えてやる。
オプションについては公式マニュアルを参照してほしいが、ここで扱っているものをざっくり解説すると
- -3 : 3’フランキング領域の長さ(デフォルト300)
- -5 : 5’フランキング領域の長さ(デフォルト300)
- -b : blastのアウトプットファイルの出力先のパス。TSVフォーマットで出力される。
- -c : 完全なCDSだとみなすための最小のカバレッジ。0-1の値で設定(デフォルト0.85、つまり85%以上で完全なCDSだと判定)
- -l : 完全なCDSとみなすための最小限の長さ(デフォルト0)
- -f : アウトプットのフォーマット。bed or gtf (デフォルトはbed)。GTFで出力したいならこれを指定。
- – p : 使うスレッド数。BLASTを動かすのでCPUパワーが物を言う。(補足: exonerate, genewise に対しても有効)
- – g : 遺伝子構造予測に使うプログラム。 exonerate か genewise を選択できるが exonerate のほうが良いと言われている(補足: と思っていたが、exonerateのほうが高速な代わりに不正確な場合が多々ある模様。正確を要求するならgenewiseを使ったほうが良い)
- -o : どれだけクエリの境界についてオーバーラップ・ギャップを許すかどうか
- -v : 1つのクエリで複数の候補が取れてくるがどれだけその数を取ってくるか。例えば1だと上位1つだけを取ってくる。
- -h : ホモロジー検索エンジンの選択。 blastn、dc-megablast、megablast、tblastn、tblastn-fast から選べる。
- -i : 初期のヒットを組み立てるための最大インターバルの長さ(エキソン間の長さ?) (デフォルト100000)
- -m : blastがヒットしたときに維持しておく最大の回数(デフォルト 500)
- -n : 遺伝子座名のプレフィックス。出力時に出てくる名前を変えられる(デフォルト locus)
- -s : スプライスジャンクションのGT-AGルールを強制させる。
- -t : 出力するものの選択。+1:機能遺伝子を出力、+2:Truncated(途中でNなどで切断されてしまっている)遺伝子を出力、+4:偽遺伝子を出力。例えば機能遺伝子とTruncatedの遺伝子だけを出力したいときは3をオプションに加える。
- -w : CR+LFの改行コードを使う
こんな感じで実行してやるとゲノム上の位置を示したbedファイルが取れてくる。
bed形式の見方であるが、特筆すべきは”RGB”のところであろう。9列目に当たる。
ここがR(255,0,0)であれば偽遺伝子、Yellow(255,255,0)であればtruncated genes、Blue(0,0,255)であれば機能遺伝子であるとの予測がついている。
bedtools で配列の取得
このbedファイルとゲノムデータをもとに配列を取得することができる。bedtoolsが必要だがこれもUbuntuならパッケージが配布されているのでインストールは簡単。
$ sudo apt install bedtools
これでインストールが完了する。
さて、bedtoolsを用いて先程のbedファイルとゲノムデータから目的の配列を取得する。
$ bedtools getfasta -split -fi [genome.fasta] -bed [out.bed] -fo [out.fasta]
out.bedは先程のFATEによる出力ファイルだ。-split でイントロンを省くことができる。
以上がFATEを用いた配列取得の流れである。
Filterの機能
似たような配列であるが別の遺伝子であるようなものは結構存在する。例えばKeratinを例にとってもKeratin以外の中間径フィラメントの遺伝子が取れてきたりする。そういったものに対していちいちBLASTをかけて「これはKeratin、これは違う」といった分け方をするのは効率が悪い。
そこでこのFATEのFilter機能を使うことで「キーワード検索」のようにある特定のキーワードを含む遺伝子についてのみ配列を抽出するといったようなことができる。
先程のbedファイルが必要となる。
$ fate.pl filter -d [タンパク質データベース.fasta] -h blastx -k 'keyword' -r 5 [ゲノムデータ] [bedファイル] > out.bed
同じような要領で使うことができる。これについても実際の塩基配列がほしければbedtoolsを使う。
Predict の機能
PredictはcDNA配列からコーディング領域を取ってくることができる。
$ fate.pl predict -h blastx -g exonerate [タンパク質データベース.fasta] [cDNA.fasta] > out.bed
これによってcDNAからコーディング領域を得ることができる。
最後に
FATEの機能の大まかな説明をしてきた。私は主にSearchを使ってゲノムデータから特定の遺伝子の配列を取り出すことに使っている。特にアノテーションもされていないような新しく読まれたゲノムに対していち早く欲しい遺伝子がないかを探したりするのに使っている。
度々バグフィックスが行われているようなので、随時アップデートしていくと良いかもしれない。
開発者ご本人(hikoyu様)より補足
FATE開発者です。拙作を紹介して頂きありがとうございます。
せっかくなのでいくつかコメントさせてください。
まず、macOSの方はhomebrewでbrewsci/bioリポジトリをtapすると、FATEが依存するBLAST+以外のソフトウェアたちをお手軽にインストールできます。(BLAST+はhomebrew-coreに含まれているのでtapしなくてもインストール可能)
“`
$ brew tap brewsci/bio
$ brew install genewise exonerate
“`
なお、genewiseに関しては、FATEに同梱しているwise2_installer.shでもコンパイルできるようにしています。(macOS、Linux両用。コンパイラーにclangを使用し、glib2とpkg-configを必要とするので、これらはhomebrewやaptなどのパッケージ管理ソフトでインストールしておく。macOSならclangはデフォルトコンパイラーなので最初から入っています)
次に遺伝子構造予測のエンジンですが、genewiseとexonerateでどちらが良いかは対象にもよります。
計算速度はexonerateの方が圧倒的に速いのですが、クエリーが遺伝的に遠い配列の場合、exonerateだと遺伝子構造予測が不正確なことが多々あります。
そのような場合、遅くてもgenewiseを使った方が良いです。
逆に、同種のクエリー配列であるとか、遺伝子構造が単純な場合などはexonerateでも充分だと思われます。
あと、genewiseはアミノ酸配列の代わりにhmmer2(hmmer3からも変換可能)で作ったアミノ酸配列の隠れマルコフモデル(HMM)を読み込ませることができるので、これを今後FATEでも実装するかもしれません。
ちなみに、FATEの並列化はBLAST検索以外に、exonerate/genewiseのプロセスを並列実行することにも効いています。



FATE開発者です。拙作を紹介して頂きありがとうございます。
せっかくなのでいくつかコメントさせてください。
まず、macOSの方はhomebrewでbrewsci/bioリポジトリをtapすると、FATEが依存するBLAST+以外のソフトウェアたちをお手軽にインストールできます。(BLAST+はhomebrew-coreに含まれているのでtapしなくてもインストール可能)
“`
$ brew tap brewsci/bio
$ brew install genewise exonerate
“`
なお、genewiseに関しては、FATEに同梱しているwise2_installer.shでもコンパイルできるようにしています。(macOS、Linux両用。コンパイラーにclangを使用し、glib2とpkg-configを必要とするので、これらはhomebrewやaptなどのパッケージ管理ソフトでインストールしておく。macOSならclangはデフォルトコンパイラーなので最初から入っています)
次に遺伝子構造予測のエンジンですが、genewiseとexonerateでどちらが良いかは対象にもよります。
計算速度はexonerateの方が圧倒的に速いのですが、クエリーが遺伝的に遠い配列の場合、exonerateだと遺伝子構造予測が不正確なことが多々あります。
そのような場合、遅くてもgenewiseを使った方が良いです。
逆に、同種のクエリー配列であるとか、遺伝子構造が単純な場合などはexonerateでも充分だと思われます。
あと、genewiseはアミノ酸配列の代わりにhmmer2(hmmer3からも変換可能)で作ったアミノ酸配列の隠れマルコフモデル(HMM)を読み込ませることができるので、これを今後FATEでも実装するかもしれません。
ちなみに、FATEの並列化はBLAST検索以外に、exonerate/genewiseのプロセスを並列実行することにも効いています。
hikoyu 様
補足解説、ありがとうございます
記事に上記のコメントを補足として掲載させていただきます
きむ